

Maschinen können mithilfe von Künstlichen-Intelligenz-Algorithmen Fotos oder Sprachdateien erzeugen, die wie aus dem wahren Leben aussehen oder klingen. Wie man solche als Deepfakes bezeichneten künstlich erzeugten Daten von echten unterscheiden kann, interessiert Forschende am Horst-Görtz-Institut für IT-Sicherheit der RUB. Sie stellten fest, dass sich echte und gefälschte Sprachdateien im Bereich der hohen Frequenzen unterscheiden. Zuvor waren Deepfakes hauptsächlich bei Bildern untersucht worden. Die neuen Erkenntnisse sollen künftig helfen, auch gefälschte Sprache erkennen zu können.
Ihre Ergebnisse stellten Joel Frank vom Lehrstuhl für Systemsicherheit und Lea Schönherr aus der Arbeitsgruppe Kognitive Signalverarbeitung am 7. Dezember 2021 auf der Conference on Neural Information Processing Systems vor, die als Online-Veranstaltung abgehalten wurde. Die Arbeiten fanden im Rahmen des Exzellenzclusters CASA – Cybersecurity in the Age of Large-Scale Adversaries statt.
Großer Deepfake-Datensatz erzeugt
Als ersten Schritt erzeugten Joel Frank und Lea Schönherr einen umfangreichen Datensatz mit rund 118.000 künstlich erzeugten Sprachdateien. So entstanden etwa 196 Stunden Material auf Englisch und Japanisch. „Solch einen Datensatz für Audio-Deepfakes hat es zuvor nicht gegeben“, erklärt Lea Schönherr. „Um die Methoden zur Erkennung von gefälschten Audiodateien zu verbessern, braucht man aber dieses Material.“ Damit der Datensatz möglichst breit aufgestellt ist, nutzte das Team sechs verschiedene Künstliche-Intelligenz-Algorithmen beim Erzeugen der Audioschnipsel.
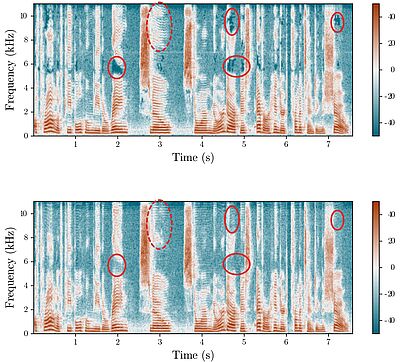
Video Deepfakes: Echte und gefälschte Datei im Vergleich
Anschließend verglichen die Forschenden die künstlichen Audiodateien mit Aufnahmen echter Sprache. Sie stellten die Dateien in Form von Spektrogrammen dar, die die Frequenzverteilung über die Zeit hinweg zeigen. Der Vergleich ergab feine Unterschiede im Bereich der hohen Frequenzen zwischen echten und gefälschten Dateien.
Basierend auf diesen Erkenntnissen entwickelten Frank und Schönherr Algorithmen, die zwischen Deepfakes und echter Sprache unterscheiden können. Diese Algorithmen sind als Startpunkt für andere Forscher gedacht, um neue Erkennungsmethoden zu entwickeln.
Originalveröffentlichung
Joel Frank, Lea Schönherr: WaveFake: A Data Set to Facilitate Audio Deepfake Detection, Thirty-fifth Conference on Neural Information Processing Systems (NeurIPS) - Track for Datasets and Benchmarks, 2021, Online-Tagung (https://nips.cc/), Paper-Download: https://arxiv.org/abs/2111.02813
Pressekontakt
Joel Frank
Lehrstuhl für Systemsicherheit
Horst-Görtz-Institut für IT-Sicherheit
Ruhr-Universität Bochum
E-Mail: joel.frank(at)rub.de
Lea Schönherr
Arbeitsgruppe Kognitive Signalverarbeitung
Horst-Görtz-Institut für IT-Sicherheit
Ruhr-Universität Bochum
Tel.: +49 234 32 29638
E-Mail: lea.schoenherr(at)rub.de
Allgemeiner Hinweis: Mit einer möglichen Nennung von geschlechtszuweisenden Attributen implizieren wir alle, die sich diesem Geschlecht zugehörig fühlen, unabhängig vom biologischen Geschlecht.